

Intro to Tokenization in Python
Tokenization in Python is the most measure in any natural language processing application. This may find its utility in statistical analysis, parsing, spell-checking, highlighting and corpus generation etc.. Tokenizer is a Python (2 and 3) module.
Why Tokenization in Python?
Natural Language Processing or NLP is a computer science field with studying involved pc sociological and artificial intelligence and mainly the interaction between individual natural languages and computer.By utilizing NLP, computers are programmed to process natural language. Tokenizing a information only means dividing body of the text. The procedure is Python text strings are changed to streams of token objects. It is to be mentioned that every token is another term, number, email, punctuation sign, URL/URI etc.. There is also segmentation to streams of sentences having dates and abbreviation in the middle of the sentences of tokens. Tokenizer is licensed under the MIT license.
Object: Token
As discussed above, every token is represented with a
The sort field: It contains one of the following integer constants which are defined under the TOK class.
The txt field: It comprises the text and sometimes it is discovered that the tokenizer auto-corrects the source text. It is seen to convert the single and double quotes to the Icelandic ones.
The val field: This field comprises information that is auxiliary according to the corresponding token.
Installation: You are able to clone the repository from: https://github.com/mideind/Tokenizer
If one wished to conduct the evaluations that are built-in, pytest can be installed by them. Then cd to Tokenizer and you also must activate your virtualenv, then conduct.
Python -m pytest
Approaches to Perform Tokenization in Python
Below are listed the number of methods to perform Tokenization:
Python’s split purpose Using Regular Expressions with NLTK
spaCy library
Tokenization using Keras
Tokenization with Gensim
Example to Implement Tokenization in Python
Here are the case of Tokenization in Python
Example #1
Python’s split function: This is the most basic one and it also returns a list of strings following dividing the series according to a particular separator.The separators can be changed as necessary. Sentence Tokenization: Here the sentence’s structure is analyzed. As we are aware that a sentence ends with a period(.) It can be used as a separator.
Code:
Text””” This tool is an a beta stage. Alexa developers can use Get Metrics API to seamlessly analyse metric. It also supports custom skill model, prebuilt Flash Briefing model, and the Smart Home Skill API. You can use this tool for creation of monitors, alarms, and dashboards that spotlight changes. The release of these three tools will enable developers to create visual rich skills for Alexa devices with screens. Amazon describes these tools as the collection of tech and tools for creating visually rich and interactive voice experiences. “””
Info = text.split-LRB-‘.’-RRB-
for I in data:
print (I)
Output:

Word Tokenizer: It functions similar as a sentence tokenizer. This textis divide upinto token according to (‘ ‘-RRB- as the separator.We provide nothing as the parameter it divides by space by deafult.
Code:
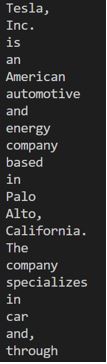
Text””” Tesla, Inc. is an American automotive and energy company based in PAlo Alto, California. The company specializes in electric car manufacturing and, through its SolarCity subsidiary, solar panel manufacturing. “””
Info = text.split()
for I in data:
print (I)
Output:
Example #2
Using Regular Expressions with NLTK: Regular saying is basically a character sequence which helps us in trying to find the fitting patterns in thetext we have.The catalog employed in Python for Regular saying is re and it comes pre-installed with Python package.Example: We have imported re library use \w+ to selecting up particular words in the saying.
Code:
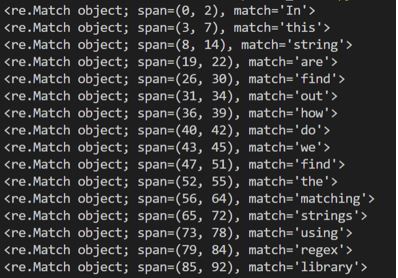
import re
text_to_search = “”” In this string you are to find out, how do we find the matching strings using regex library “””
pattern = re.compile(‘\w+’)
matches = pattern.finditer(text_to_search)
for match in matches:
print(match)
Output:
It is to be mentioned that nltk needs before we can use regular expressions to be imported.
Tokenization by NLTK: This library is composed for statistical Natural Language Processing. We utilize tokenize () to Additional divide it into two types:
Word tokenize: word_tokenize() is used to divide a sentence into tokens as needed.
Sentence tokenize: sent_tokenize() is used to divide a paragraph or even a file into paragraphs.
We see in the terminal below with all the output:
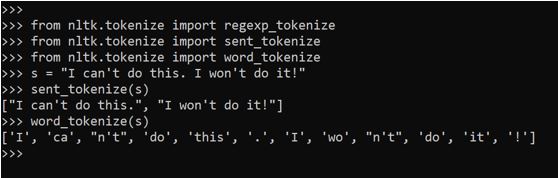
Out of import regexp_tokenize
Out of nltk.tokenize import sent_tokenize
from nltk.tokenize import word_tokenize
s =”I can’t do this. I won’t do it!”
sent_tokenize(s)
word_tokenize(s)
(The exact above output was run in cmd as I had been having some difficulty in my Visual Studio Code.)
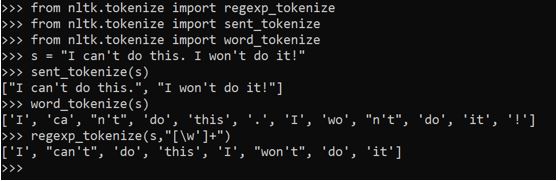
In the above case we see that the words “could ’t& & rdquo; & “won’t& & rdquo; are separated out. We follow the below strategy if that needs to be considered as a term.
We handle it by adding another line of code. By specifying [\w/ rsquo;]+ we guarantee notification python that there’s a word following the apostrophe(‘-RRB- and that also needs to be handled.
Regexp_tokenize(s,”[\w/ rsquo;]+”)
Approaches of NLTK
The tokenize() Function: When we need to tokenize a string, we use this role and we get a Python generator of token objects. Each thing is a tuple with all the fields. In Python 2.7 one can pass a unicode string or byte strings to the function tokenizer.tokenize(). And in the variant that was later it’s seen that byte string are encoded in UTF-8.
Example #3
SpaCy library: It is library for NLP. Here we make use of all spacy.lang.en which affirms the English Language.spaCy is a much faster library in comparison to nltk.
Before utilizing one needs Anaconda installed in their machine. Anaconda is a package of some popular python packages along with a package manager called conda (like pip). These packages are highly popular in Data Science study. Some favorite anaconda packs are numpy, scipy, nltk(the one used previously ), jupyter, scikit-learn etc.. ) Because , it helps one to utilize non-python dependencies as well whereas pip doesn’t allows 27, the reason conda is used instead of pip is.
The input for tokenizer is a Unicode text and Doc thing is the output. Vocab is required to construct an Doc object.SpaCy’therefore tokenization could always be reconstructed to the first one and it’s to be noticed that there’s preservation of whitespace info.
Code:
import spacy
Out of spacy.tokens import Doc
from spacy.lang.en import English
nlp = English()
doc = Doc(nlp.vocab, words = [“Hello”,”,”,”World”,”!”] , spaces = [False, True, False, False])
print([(t.text, t.text_with_ws, t.whitespace_) for t in doc])
Output:

Example #4
Tokenization with Keras: It is but one of the profound learning frameworks that are most dependable. It is an open-source library in python for neural network. We can install it using: pip set up Keras. To perform tokenization we utilize: text_to_word_sequence method in the Classkeras.preprocessing.text course. 1 thing about Keras is that it converts the alphabet prior to tokenizing it in lower case and thus valuable in time conserving.
Code:
Out of keras.preprocessing.text import text_to_word_sequence
# define exactly the text
text =’Text to Word Sequence Function works really well’
# tokenizing the text
traces = text_to_word_sequence(text)
print(tokens)
Output:
![]()
Example #5
Tokenization with Gensim: This open minded library is devised at extracting semantic topics and has found great utility in unsupervised topic modelling and in NLP. It is to be mentioned that Gensim is very certain about the punctuations in the series.
Code:
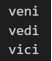
Out of gensim.summerization.textcleaner import tokenize_by_word
G = tokenize_by_word(‘Veni. Vedi. Vici. ‘)
Print (next(gram ))
print(adjacent (gram ))
print(adjacent (gram ))
Output:
Conclusion
Tokenization is a helpful step at solving a NLP application. As we will need to manage the unstructured information before we start with the procedure. Tokenization comes useful as the first and the foremost step.
Recommended Articles
This is a direct to Tokenization at Python. Here we talk introduction to Tokenization in Python, methods, examples with code and presses. You can also go through our articles that are related to find out
NLP in Python
Install NLTK
Data Mining vs Text Mining
NLP Interview Questions
The post Tokenization in Python appeared on EDUCBA.
Article Source and Credit educba.com https://www.educba.com/tokenization-in-python/ Buy Tickets for every event – Sports, Concerts, Festivals and more buytickets.com
Leave a Reply
You must be logged in to post a comment.