
In a world focused on algorithms and models, you’d be forgiven for denying the value of quality and information preparation . This is actually the garbage in, garbage out principle: faulty data moving in leads to faulty results, algorithms, and business choices. When a car&rsquo algorithm will be trained on information of traffic you wouldn’t even place it during the night on the roads. To carry it a step farther, if this algorithm is educated with cars driven by humans in a environment, how can you expect it to perform well on roads with other cars? Past the autonomous driving example described, the “garbage in” side of this equation could take several forms–for instance, incorrectly entered information collected more of which individuals & rsquo; ll address below, and data, poorly packed data.
When executives inquire how to approach an AI transformation, then I show them Monica Rogati’s AI Hierarchy of Needs, which has AI on Top, and that which has been built upon the base of information (Rogati is a statistics science and AI advisor, former VP of information at Jawbone, along with preceding LinkedIn data scientist):
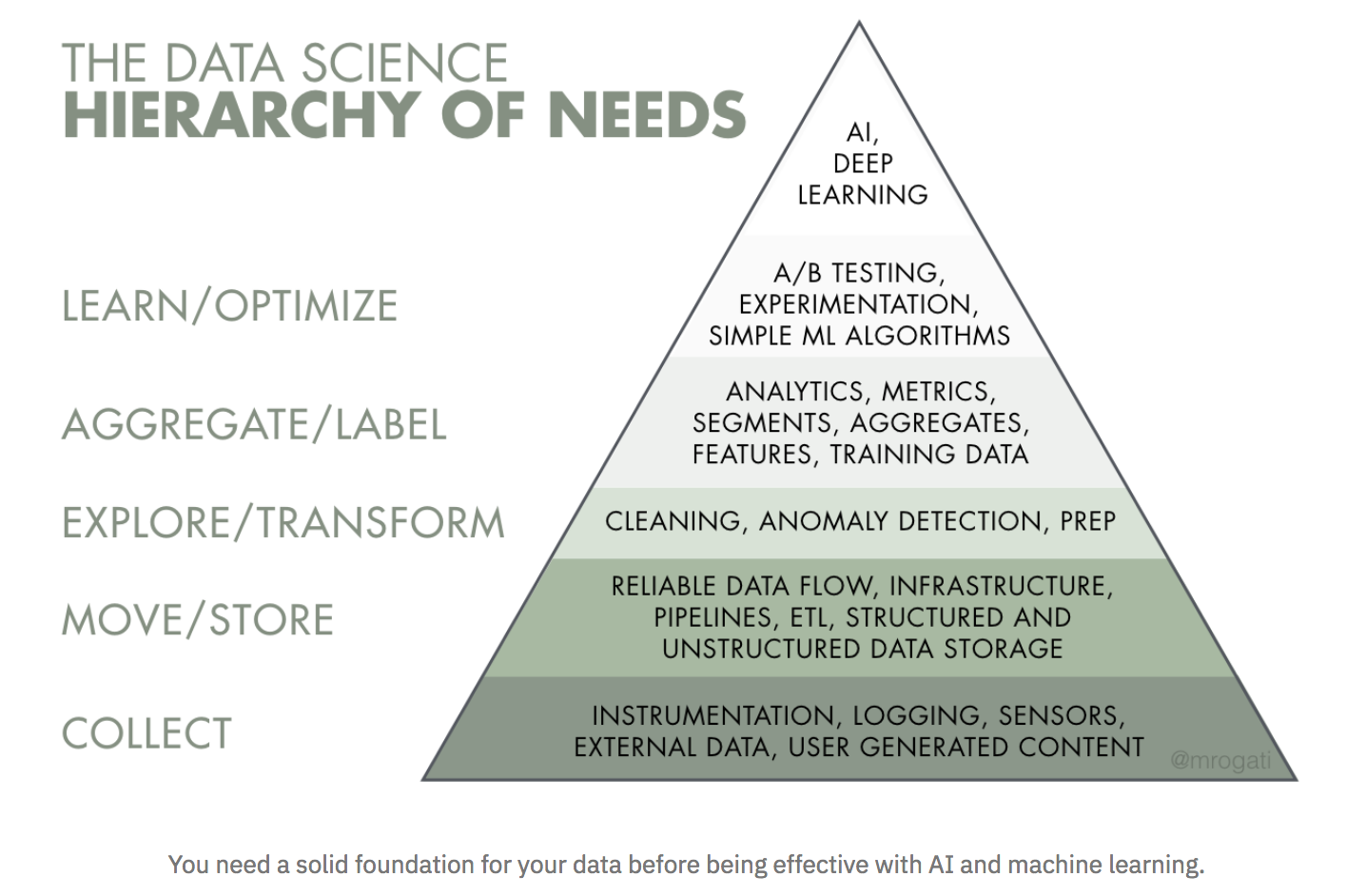 Image courtesy of Monica Rogati, used with permission.
Image courtesy of Monica Rogati, used with permission.
Why is accessible and high-quality data foundational? If the results of experiments and also you & rsquo; re basing business decisions on dashboards, you will need to have the data that is perfect. About the machine learning facet, we’re entering the Andrei Karpathy, director of AI at Tesla, dubs the Software 2.0 era, a new paradigm for software by which machine learning and AI require less attention on writing code and much more about configuring, selecting input signal, along with iterating through information to produce increased level models that learn from the information we give them. In this universe, data has become a citizen, in which computation becomes probabilistic and programs no longer do the exact identical thing. The design and the information specification eventually become more significant.
Collecting the information requires a principled approach that’s a part of your business question. Data gathered for one purpose could have restricted use for questions. The assumed value of information is a myth resulting in inflated valuations of start-ups capturing information that is mentioned. John Myles White, information scientist and technology director at Facebook, composed: “The biggest risk I see data science endeavors is that analyzing information per se is usually a terrible thing. Generating data using a pre-specified analysis plan and conducting which analysis is great. Data is often very bad. ” John is drawing attention to thinking carefully about what you expect to get out of the information, what question you aspire to answer, what biases may exist, and what you will need to fix before jumping in with an analysis[1]. With the ideal mindset, you can find a lot out of analyzing existing information –for instance, descriptive information is often quite useful for early-stage companies[2].
Not long ago, “save everything” was a frequent maxim in technology; you never knew if you may want the data. But attempting to repurpose data may muddy the water from the information was accumulated to the question you hope to answer by altering the semantics. In particular, determining causation can be challenging. By Way of Example, a preexisting correlation pulled from a company ’s database Ought to Be tested in a new experiment and not assumed to suggest causation[3], instead of the often encountered pattern in technology:
A large fraction of consumers who do X do Z
Z is great Let’s get everyone to do X
Correlation in present data is proof for causation that needs to be confirmed by collecting information.
Research is plagued by the challenge. Take the case of Brian Wansink, former leader of the Food and Brand Lab at Cornell University, who stepped down after a Cornell faculty review reported that he “dedicated academic misconduct in his research and scholarship, including misreporting of research information, problematic statistical techniques [and] failure to correctly document and maintain research benefits. ” One of the more egregious mistakes was to always test already collected statistics for new hypotheses till one stuck, after his first hypothesis failed[4]. NPR put it nicely : “the gold standard of scientific studies is to produce a single hypothesis, collect data to examine it, and analyze the results to see if it holds up. By Wansink’s admission in the article, that’s not what happened in his laboratory. ” He always tried to fit hypotheses irrelevant to the information gathered until he acquired a hypothesis using an acceptable p-value –even a perversion of the scientific system.
Information professionals devote an amount punctually fixing cleaning, and preparing information
Before you even think about complex modeling system learning, and AI, you need to make sure that your data is prepared for analysis. You may envision data scientists building machine learning models daily, but the frequent trope that they spend 80 percent of their time on data prep is nearer to the fact .

That is old news in lots of ways, however it’s older news which still disturbs usa recent O’Reilly survey found that lack of information or information quality problems was among the key bottlenecks for additional AI adoption for businesses at the AI test stage and was the main bottleneck for businesses with mature AI clinics.
Good quality datasets are alike, but each low end dataset is low in its very own way[5]. Data could be low if:
It doesn’t even fit your question or its set wasn’t carefully considered;
It’s erroneous (it might say “cicago” for a place ), inconsistent (it might say “cicago” in 1 location and also “Chicago” in another), or missing;
It’s great information but packed in a horrible way–e.g., it’s stored across a variety of siloed databases in an organization;
It demands human tagging to be useful (like manually tagging emails as “spam” or “not” for a spam detection algorithm).
Quality is defined by this definition of information as a function of how much work is required to find the information. Look at the answers to my tweet for information quality nightmares that contemporary data professionals grapple with.
The Value of automating data prep
Most of the conversation about AI automation involves automating machine learning models, a field known as AutoML. That is important: think about how many contemporary models will need to function at scale and in real time (like Google’s search engine as well as the relevant tweets which Twitter surfaces on your feed). In addition, we have to be talking about automation of steps in the information science workflow/pipeline, such as those at the beginning. Why is it significant to automate data prep?
It occupies an inordinate quantity of time for information professionals. Information drudgery automation in the era of information smog will spare information scientists up for doing more intriguing, innovative work (for instance, modeling or interfacing with company inquiries and insights). “76% of information scientists see data prep as the least fun part of their job,” based on a CrowdFlower poll .
Your analysis can be biased by A string of subjective data prep micro-decisions. For instance, data with values that are missing could throw out, yet another could infer the values. To learn more about how micro-decisions in diagnosis can affect results, I urge Many Analysts, One Data Set: Making Transparent How Variations in Analytic Choices Affect Results[6] (note that the analytic micro-decisions in this research are not only data prep decisions). & rsquo was won by data prep;t eliminate prejudice, but it will allow it to be discoverable systematic, auditable, unit-testable, and correctable. Model results will be reliant on people. An added plus is that the job will be reproducible and strong, in the sense that someone else (say, in another section ) can reproduce the analysis and receive exactly the same outcomes [7];
For the rising quantity of real-time algorithms in manufacturing, humans will need to be taken out of this loop at runtime as much as possible (and possibly be stored in the loop longer as algorithmic supervisors ): once you use Siri to make a booking on OpenTable by asking for a table for four at a nearby Italian restaurant tonight, then you now ’s a speech-to-text model, a geographical search design, plus a restaurant-matching model, all working together in real time. No data analysts/scientists operate on this information pipeline because everything must happen in real time, requiring an automatic data preparation and information quality workflow (e.g., to resolve if I say “eye-talian” instead of “it-atian”).
The stage above speaks generally to the need for automation pieces of the information science workflow. This need will grow as devices, IoT, voice assistants, drones reality become more widespread.
Automation represents a case of democratization, making info abilities available for the broader population. Democratization entails both education (which I focus on in my job at DataCamp) and creating tools that lots of folks can use.
Knowing the significance of overall automation and democratization of parts of the DS/ML/AI workflow, it’s crucial to recognize that we’ve done fairly well at democratizing information collection and collecting, mimicking [8], along with information coverage [9], however what remains stubbornly hard is the whole procedure for preparing the information.
Modern tools for data prep and automating data cleaning
We’re witnessing the emergence of contemporary tools for automatic data cleaning and planning, such as HoloClean along with Snorkel coming from Christopher Ré’s team at Stanford. HoloClean decouples the endeavor of data cleaning into malfunction detection (for instance, recognizing that the location “cicago” is erroneous) and fixing erroneous data (for instance, changing “cicago” into “Chicago”), and formalizes the fact that “data cleaning is a statistical analysis and inference issue. ” All information analysis and information science work is a mixture of assumptions information, and knowledge. When youpossess info, ” or & rsquo; re missing data you use assumptions, data, and inference to repair your own information. HoloClean performs this automatically in a principled, statistical way. The consumer needs to do is always “to specify assertions that capture their domain experience to invariants with respect that the input needs to satisfy. No other supervision is necessary! ”
The HoloClean team has a system for automating the “building and managing [of] training datasets without guide tagging ” called Snorkel. Having properly labeled data is a key part of preparing information to construct machine learning models[10]. Manually tagging it is unfeasible, as more and more information is created. Snorkel provides a means to automate tagging, employing a contemporary paradigm named info programming, where users are able to “inject domain information [or heuristics] into machine learning models in higher level, higher bandwidth manners than manually tagging tens of thousands or millions of individual data points. ” Researchers at Google AI have accommodated Snorkel to label data at industrial/web scale and demonstrated its usefulness in three scenarios: subject classification, product classification, and real time occasion classification.
Snorkel doesn’t even quit data tagging. It also allows you to automate two other aspects of Information prep:
Data enhancement — which is tagged data. Take an image recognition problem where you are attempting to detect cars in photos for your self-driving vehicle algorithm. Classically, you’ll want several thousand labeled photos. In case you don & rsquo; t have enough training information and label and it & rsquo; s pricey to collect more information, it is possible to make more.
Discovery of information that is crucial subsets which subsets of your information help to distinguish spam from non-spam.
These are just two of several present examples of this augmented data prep revolution, which includes merchandise from IBM along with DataRobot.
The potential of Information tooling and information prep as a struggle
So what does the future hold? In a universe with an increasing amount of algorithms and models of streaming information, learning from considerable quantities in production, we want both instruction and tooling/products for domain experts to construct, socialize with, and audit the relevant data pipelines.
We’ve noticed a lot of headway made in automating and democratizing building models and data collection. Just look at the emergence of drag-and-drop applications for system learning workflows coming out of Google along with Microsoft. As we saw from the current O’Reilly poll, data cleaning and preparation take up a lot of time that information professionals don&rsquo. Because of this , it’s exciting that we’re starting to view headway in tooling for data cleaning and preparation. It’ll be intriguing to observe the tools are embraced and how this distance grows.
A future could observe information quality and data preparation as first-class citizens in the information workflow, together with machine learning, profound learning, and AI. Coping with information that is incorrect or missing is unglamorous but necessary work. It’s easy to warrant working rsquo & that the only real surprise is the period of time it takes. Knowing how to handle more subtle problems with information, like information that reflects and implements historical biases (by way of instance, property redlining) is a harder organizational battle. This will call for open discussions in any organization about.
The simple fact that while information workers spend most of their time data prep, business leaders are focused on predictive models and profound learning is a challenge, not a technical one. Everyone should acknowledge and understand the challenge, Whether this area of the data stream pipeline will be solved later on.
Many thanks for Angela Bassa, Angela Bowne, Vicki Boykis, Joyce Chung, Mike Loukides, Mikhail Popov, and Emily Robinson because of their valuable and crucial feedback on drafts of the article along the way.
[1] For instance, let’s say that you have present data on the number of users in your e-commerce site have clicked items after a hunt. You have to fix the bias introduced from the order once the information was accumulated, if you want to repurpose this information later to rank your site & rsquo; s search results.
[2] For instance, Mikhail Popov, a data analyst at the Wikimedia Foundation, told me that they’re getting new illustrative analyses out of years of existing data to get new insights on their users (particularly editors) and trends. As a particular instance: among their biggest information sources is editing history across each of their jobs, publicly accessible at Analytics Datasets, which they use to answer ad-hoc questions like “across the 300 languages of Wikipedia, what % of newly enrolled accounts create an edit in their first 24 hours! ” or to look at how readership traffic (pageviews additionally accessible openly ) has connected historically with editing action — which are descriptive insights into their many communities.
[3] Related will be the ultimate focus on ldquo;large information. ” “Small information ”, when accumulated in a principled, thoughtful manner may have lots of signal. Look no farther than the simple fact that a survey of just 1,004 Americans represents 260 million people with just a 3 percent margin of error, once the sample is representative (this is seldom true but you will find complex correction methods that could get experts shut ). Similarly, “thick (or qualitative) information ” can frequently tell us more than merely collecting more and more “large info ”.
[4] This is an example of exactly what ’s known as p-hacking.
[5] To paraphrase Hadley Wickham’s rendition of Tolstoy in this newspaper .
[6] In which 29 pro teams are awarded “exactly the same data collection to deal with the identical research question: whether football referees are more inclined to provide red cards into dark-skin-toned players than to light-skin-toned players. ” 69% said “yes” although 31 percent said “no”. What’s even more about is after seeing the teams & rsquo; analyses that most teams were even more confident of their own results. According to the newspaper, “These findings indicate that significant variation in the results of analyses of complex data might be difficult to avoid, even by experts with honorable intentions. ”
[7] Yet another benefit is that building such automatic data prep pipelines is basically a type of preregistering analytical methods (specifying your strategy before actually doing it so that you can’t even alter it like a part of everything you see in your information ), which also reduces individual prejudice. A growing number of research scientists are increasingly advocating for preregistration, particularly with the continuing reproducibility catastrophe in scientific research, together with its own legitimacy catastrophe .
[8] With automatic machine learning packs like TPOT and drag-and-drop interfaces like Azure’s automatic machine learning tool.
[9] Such as R Markdown along with Jupyter Notebooks.
[10] For instance, if you’re building a spam detection model, then you have to feed the model both spam and non-spam mails, labeled properly as “crap ” or “non-spam” (called training information as you use it in order to train your version ). To observe how significant the challenge of having great quality labelled information, look no farther than info labelling start-up Scale AI’s recent $100 million Series C financing round, which attracted their evaluation past $1 billion (also note that Scale AI is still using humans to label their information to the back end).
Article Source and Credit feedproxy.google.com http://feedproxy.google.com/~r/oreilly/radar/atom/~3/Pt-JBUG44GM/ Buy Tickets for every event – Sports, Concerts, Festivals and more buytickets.com
Leave a Reply
You must be logged in to post a comment.